Confiabilidad.
La confiabilidad es otro requerimiento indiscutible – y probablemente el más importante. Una base de datos no confiable es simplemente inutilizable. Para la mayoría de las aplicaciones empotradas, en especial las empleadas en sistemas de tiempo real, la confiabilidad es una propiedad no negociable que deben tener todos los componentes.
Un sistema de manejo de bases de datos confiable es aquel que puede continua procesando las solicitudes de usuario aún cuando el sistema sobre el que opera no es confiable. En otras palabras, aun cuando los componentes de un sistema distribuido fallen, un DDMBS confiable debe seguir ejecutando las solicitudes de usuario sin violar la consistencia de la base de datos.
4.3.1 Conceptos básicos de confiabilidad.
La confiabilidad engloba varias actividades y una de ellas es el planteamiento de modelos de confiabilidad, esto es fundamentalmente la probabilidad de supervivencia del sistema.
Se expresa como una función de las confiabilidades de los componentes o subsistemas, que generalmente, estos modelos se encuentran dependiendo del tiempo.
4.3.2 Protocolos REDO/UNDO.
El registro de la base de datos contiene información que es utilizada por el proceso de recuperación para restablecer la base de datos a un estado consistente. Esta información puede incluir entre otras cosas:
- el identificador de la transacción,
- el tipo de operación realizada,
- los datos accesados por la transacción para realizar la acción,
- el valor anterior del dato (imagen anterior), y
- el valor nuevo del dato (imagen nueva).
Considere el escenario mostrado en la Figura de abajo. El DBMS inicia la ejecución en el tiempo 0 y en el tiempo t se presenta una falla del sistema. Durante el periodo [0, t] ocurren dos transacciones, T1 y T2. T1 ha sido concluida (ha realizado su commit) pero T2 no pudo ser concluida.
La propiedad de durabilidad requiere que los efectos de T1 sean reflejados en la base de datos estable. De forma similar, la propiedad de atomicidad requiere que la base de datos estable no contenga alguno de los efectos de T2.
Ejemplo de una falla del sistema.
A pesar que T1 haya sido terminada, puede suceder que el buffer correspondiente a la página de la base de datos modificada no haya sido escrito a la base de datos estable. Así, para este caso la recuperación tiene que volver a realizar los cambios hechos por T1. A esta operación se le conoce como REDO y se presenta en la Figura de abajo.
La operación de REDO utiliza la información del registro de la base de datos y realiza de nuevo las acciones que pudieron haber sido realizadas antes de la falla. La operación REDO genera una nueva imagen.
Operación REDO.
Por otra parte, es posible que el administrador del buffer haya realizado la escritura en la base de datos estable de algunas de las páginas de la base de datos volátil correspondientes a la transacción T2.
Así, la información de recuperación debe incluir datos suficientes para permitir deshacer ciertas actualizaciones en el nuevo estado de la base de datos y regrasarla al estado anterior. A esta operación se le conoce como UNDO y se muestra en la Figura de abajo. La operación UNDO restablece un dato a su imagen anterior utilizando la información del registro de la base de datos.

Operación UNDO.
De forma similar a la base de datos volátil, el registro de la base de datos se mantiene en memoria principal (llamada los buffers de registro) y se escribe al almacenamiento estable (llamadoregistro estable). Las páginas de registro se pueden escribir en el registro estable de dos formas: síncrona o asíncrona. En forma síncrona, también llamada un registro forzado, la adición de cada dato en el registro requiere que la página del registro correspondiente se mueva al almacenamiento estable. De manera asíncrona, las páginas del registro se mueven en forma periódica o cuando los buffers se llenan.

4.3.3 Puntos de verificación (checkpoints).
Cuando ocurre una falla en el sistema es necesario consultar la bitácora para determinar cuáles son las transacciones que necesitan volver a hacerse y cuando no necesitan hacerse. Estos puntos de verificación nos ayudan para reducir el gasto de tiempo consultando la bitácora. El punto de verificación es un registro que se genera en la bitácora para concluir en todo lo que se encuentra antes de ese punto está correcto y verificado.
4.3.4 Protocolo 2PC de confiabilidad distribuida.
El protocolo 2PC básico un agente (un agente-DTM en el modelo) con un rol especial. Este es llamado el coordinador; todos los demás agentes que deben hacer commit a la vez son llamados participantes.
El coordinador es responsable de tomar la decisión de llevar a cabo un commit o abort finalmente. Cada participante corresponde a una subtransacción la cual ha realizado alguna acción de escritura en su base de datos local.
Se puede asumir que cada participante está en un sitio diferente. Aun si un participante y el coordinador se encuentran en el mismo sitio, se sigue el protocolo como si estuvieran en distintos sitios.
La idea básica del 2PC es determinar una decisión única para todos los participantes con respecto a hacer commit o abort en todas las subtransacciones locales.
El protocolo consiste en dos fases:
- La primera fase tiene como objetivo alcanzar una decisión común,
- La meta de la segunda fase es implementar esta decisión.
El protocolo procede como sigue:
Fase uno:
• El coordinador escribe “prepare” en la bitácora y envía un mensaje donde pregunta a todos los participantes si preparan el commit (PREPARE).
• Cada participante escribe “ready” (y registra las subtransacciones) en su propia bitácora si está listo o “abort” de lo contrario.
• Cada participante responde con un mensaje READY o ABORT al coordinador.
• El coordinador decide el commit o abort en la transacción como un resultado de las respuestas que ha recibido de los participantes. Si todos respondieron READY, decide hacer un commit. Si alguno ha respondido ABORT o no ha respondido en un intervalo de tiempo determinado se aborta la transacción.
Fase dos:
• El coordinador registra la decisión tomada en almacenamiento estable; es decir, escribe “global_commit” o “global_abort” en la bitácora.
• El coordinador envía mensaje de COMMIT o ABORT según sea el caso para su ejecución.
• Todos los participantes escriben un commit o abort en la bitácora basados en el mensaje recibido del coordinador (desde este momento el procedimiento de recuperación es capaz de asegurar que el efecto de la subtransacción no será perdido).
Finalmente:
- Todos los participantes envían un mensaje de acuse de recibo (ACK) al coordinador, y ejecutan las acciones requeridas para terminar (commit) o abortar (abort) la subtransacción.
- Cuando el coordinador ha recibido un mensaje ACK de todos los participantes, escribe un nuevo tipo de registro en la bitácora, llamado un registro “completo”.











 ,
, 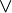 , combinándolos con operadores
, combinándolos con operadores  .
.
 son atributos de la relación R .
son atributos de la relación R .

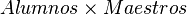

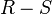

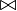 ) (Natural Join)
) (Natural Join) es la igualdad Clave Primaria = Clave Externa (o Foranea), y la proyección elimina la columna duplicada (clave externa).
es la igualdad Clave Primaria = Clave Externa (o Foranea), y la proyección elimina la columna duplicada (clave externa).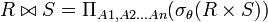

 en A.
en A.